A software architecture pattern is a “general, reusable solution to a commonly occurring problem in software architecture within a given context.”
Wikipedia
Our industry spends a lot of time and resources to define and understand architectural patterns because building software is hard, especially when we want to maintain it over time with larger teams.
Patterns discussed here:
- Layered architecture
- Hexagonal architecture
- Onion architecture
- Package by feature
- Clean architecture
Software architecture concepts
- Cohesion
- Coupling
- Separation of concerns
- Layers of isolation
- Dependency inversion principle (DIP)
- Inversion of control (IOC)
Grzegorz Ziomonski has a good overview of these architectural patterns. His approach is to describe the principles of each, identify pros and cons, and to see how the architecture would affect a project. His analysis is sometimes shallow, however, so it is important to refer to more authoritative literature, such as that written by the creator of a pattern.
Introduction
Why should we look at architecture? In his article Screaming Architecture, Robert “Uncle Bob” Martin describes good architecture like this:
A good software architecture allows decisions about frameworks, databases, web servers, and other environmental issues and tools, to be deferred and delayed. A good architecture makes it unnecessary to decide on Rails, or Sprint, or Hibernate, or Tomcat or MySql, until much later in the project. A good architecture makes it easy to change your mind about those decisions too. A good architecture emphasizes the use-cases and decouples them from peripheral concerns.
`Robert “Uncle Bob” Martin, Screaming Architecture
Each of the architecture patterns described here provide some or all of the benefits described by Uncle Bob, but they all come with their own costs as well. We’ll try to analyze these factors as we compare the patterns.
Layered Architecture
A layered architecture organizes the project structure into horizontal layers, each layer performing a specific role within the application. While this pattern does not specify the number or types of layers that must exist, most layered architectures consist of four standard layers:
- Presentation layer
- Business layer
- Persistence layer
- Database layer
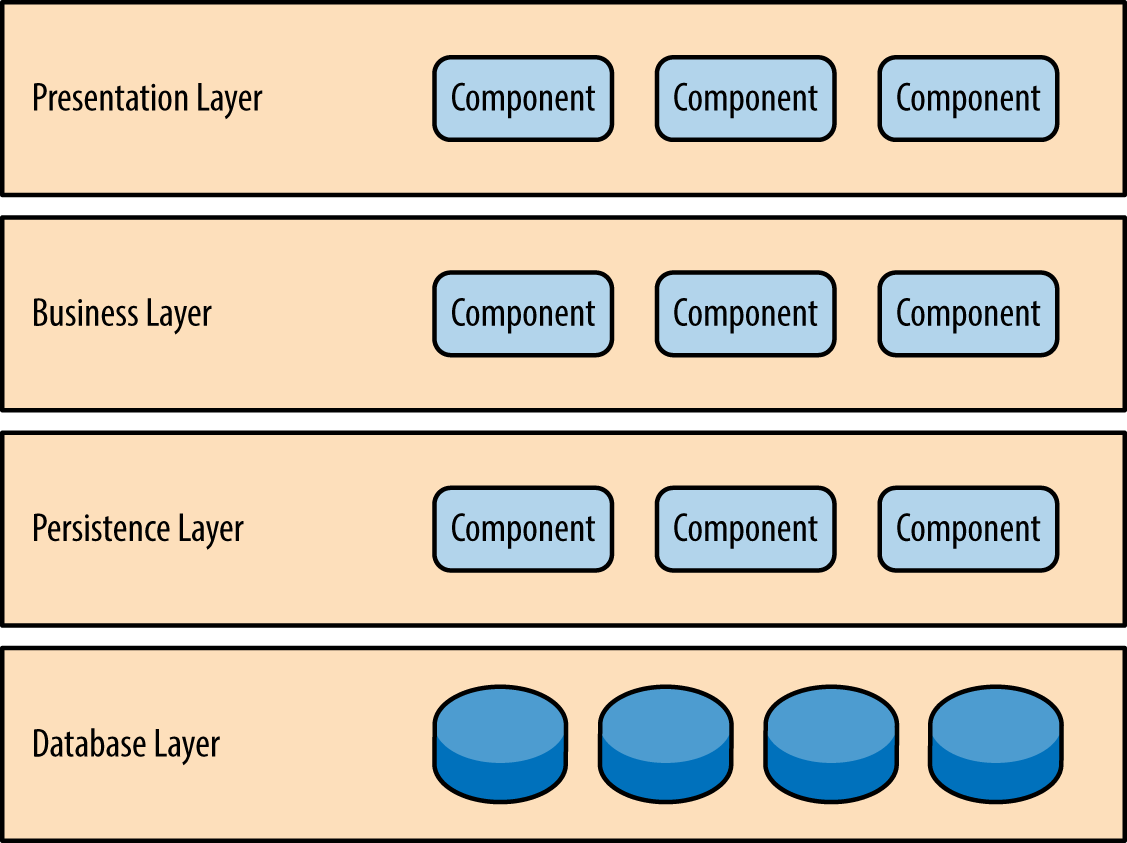
There are two important rules for this pattern:
- No logic related to one layer’s concern should be placed in another layer.
- All dependencies go in one direction.
The first rule states that no logic related to one layer’s concern should be placed in another layer.
One of the powerful features of the layered architecture pattern is the separation of concerns among components. Components within a specific layer deal only with logic that pertains to that layer. For example, components in the presentation layer deal only with presentation logic, whereas components residing in the business layer deal only with business logic. This type of component classification makes it easy to build effective roles and responsibility models into your architecture, and also makes it easy to develop, test, govern, and maintain applications using this architecture pattern due to well-defined component interfaces and limited component scope.
Mark Richards, Software Architecture Patterns
The second rule states that all dependencies go in one direction. In its simplest form, an implementation of the layered architecture pattern would dictate that components in one layer can only depend on components in the layer directly below it, known as a closed layer. This concept is known as layers of isolation. This concept means that changes made in one layer of the architecture generally don’t impact or affect components in other layers. This reduces coupling between layers. It also means that each layer is independent of the other layers, thereby having little or no knowledge of the inner workings of other layers in the architecture.
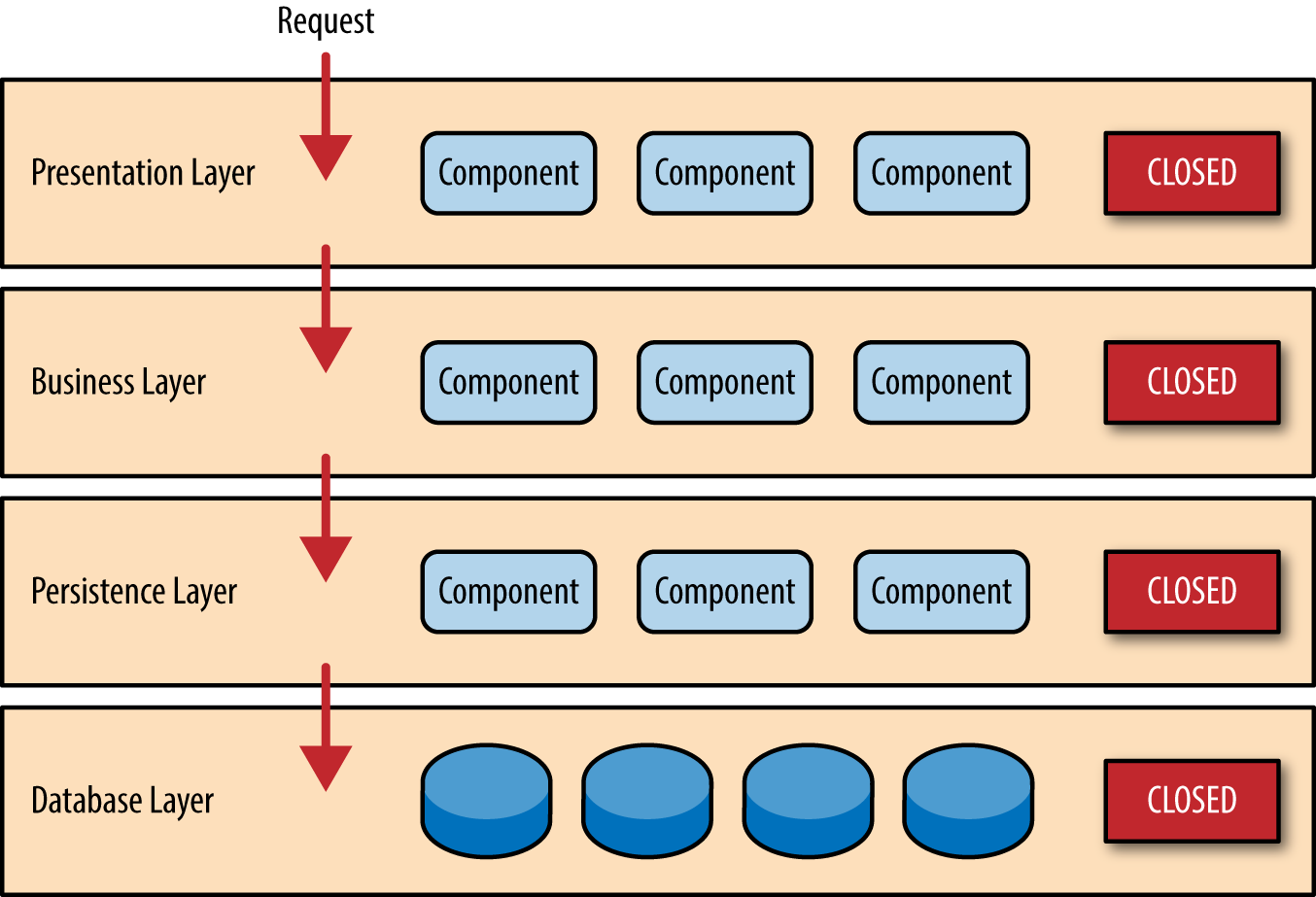
There are times when it makes sense for certain layers to be open, such as when adding shared service components (e.g. data and string utilities or auditing and logging facilities).

Analysis
| Benefit | Notes |
|---|---|
| Simplicity | The concept is very easy to learn and visible in the project by inspection. |
| Consistent across different projects | The layers and overall code organization is pretty much the same in every layered project. |
| Guaranteed separation of concerns | Developers can focus on the details of the layer they are working on. |
| Browsability from a technical perspective | When changing something in some/all objects of a given kind, they’re very easy to find and they’re kept all together. |
| Drawback | Notes |
|---|---|
| No built-in scalability | When the project grows too large, this pattern doesn’t aid in refactoring. |
| Hidden use cases | You can’t say what a project is doing by simply looking at the code organization. You need to read class names and sometimes even the implementation. |
| Low cohesion | Classes that contribute to common scenarios and business concepts are far from each other because the project is organized around separating technical concerns. |
| No dependency inversion | The pattern does not describe how dependencies should be implemented, so if components are implemented without consulting other patterns, direct dependencies are defined instead of abstractions. |
| Not use-case focused | This pattern organizes components based on type of function and does not provide any help to discover use cases when taking a high-level look at the code. |
Resources
- Layered Architecture is Good by Grzegorz Ziomonski
- Chapter 1. Layered Architecture from Software Architecture Patterns by Mark Richards (O’Reilly)
Hexagonal Architecture
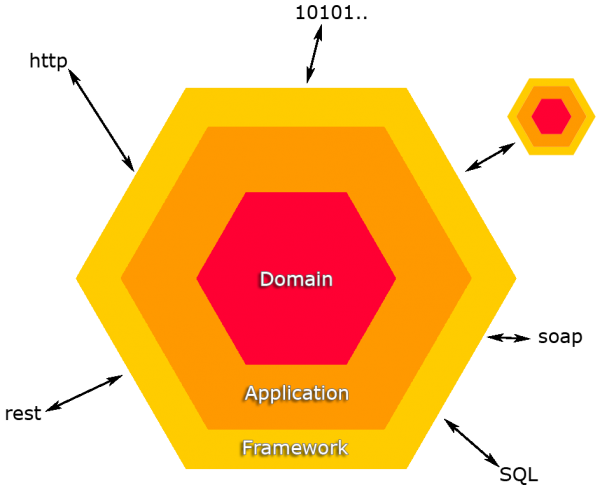
The Hexagonal Architecture – also known as the Ports and Adapters Architecture – was created by Alistair Cockburn with the primary aim of decoupling the applications core logic from the services it uses. This allows different services to be “plugged in” and it allows the application to be run without these services.
This pattern prescribes that every piece of functionality the application offers is available through an API or function call, and that the application accesses external entities (e.g. databases, networking, UI) via a well-defined interface. The application communicates over these “ports”, and an adapter is implemented for each port.
This can be build down to the following principles:
- The inside part knows nothing about the outside part.
- Any adapter that fits a given port can be used.
- No use case or domain logic is implemented in the outside part.
| Benefit | Notes |
|---|---|
| Easy to learn | It’s just ports and adapters. |
| Application and domain purity | The most important code in the application is not cluttered by technical details. |
| Flexibility | Adapters can be swapped out easily. |
| Testability | Test replacements for the outside dependencies can be provided without using extra mocking tools. |
| Drawback | Notes |
|---|---|
| Heaviness | A lot of extra classes are required, especially when only one UI and one database need to be supported. |
| Indirections | To follow the flow of control you must look at the implementation of a port and be aware of the state of the application. |
| Confusing to apply with frameworks | It’s now always clear what should be considered the outside. |
| No code organization guidelines | How code is organized is not informed by this pattern. |
| Not use-case focused | This pattern organizes components based on type of function and does not provide any help to discover use cases when taking a high-level look at the code. |
Resources
- Hexagonal Architecture is Powerful by Grzegorz Ziomonski
- Hexagonal architecture by Alistair Cockburn
- What is Hexagonal architecture by Philip Brown
- Ports-And-Adapters / Hexagonal Architecture by Patrick van Bergen
- Hexagonal Architecture by Marcus Biel
Onion Architecture
The Onion Architecture was created by Jeffrey Palermo to provide the following benefits:
- Supports long-lived applications
- Supports applications with complex behavior
- Emphasizes the use of interfaces for behavior
- Forces the externalization of infrastructure
This pattern can be viewed as an evolution and combination of the Layered Architecture and the Hexagonal Architecture.
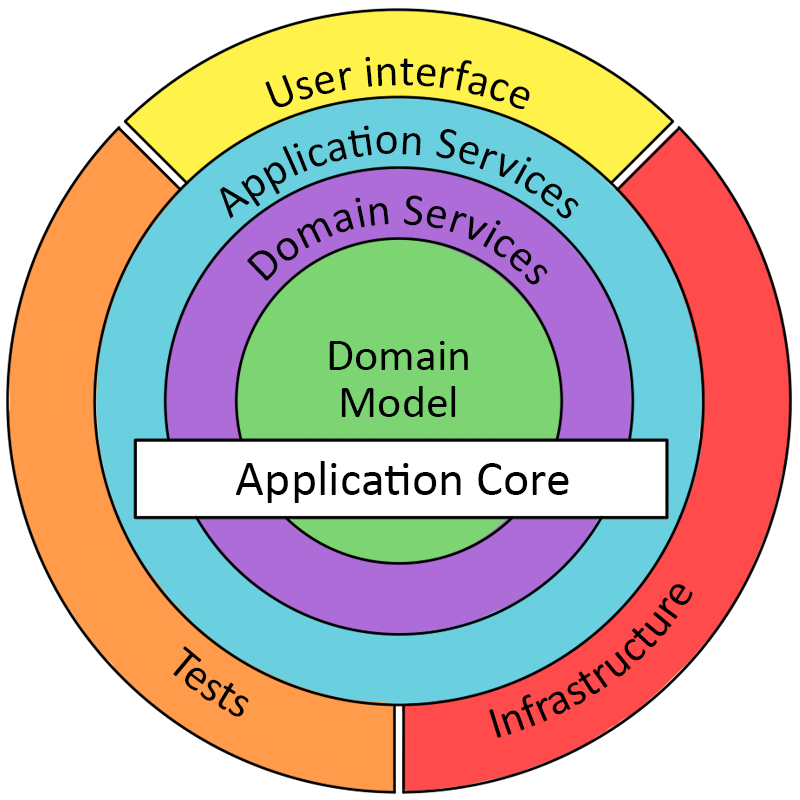
The primary differences between this pattern and the Layered Architecture are:
- Infrastructure is pulled to the outer ring (aka top layer).
- Dependency layers are open.
- The Dependency Inversion Principle is prescribed for defining communication between layers.
It shares the following premise with the Hexagonal Architecture:
- Externalize infrastructure and write adapter code so that the infrastructure does not become tightly coupled.
Key tenets of the Onion Architecture:
- The application is built around an independent object model.
- Inner layers define interfaces. Outer layers implement interfaces.
- Direction of coupling is toward the center.
- All application core code can be compiled and run separate from infrastructure.
Dependency Inversion Principle
As mentioned above, the Dependency Inversion Principle is core to this pattern. This principle refers to a specific form of decoupling software modules that reverses the conventional dependency relationship.
- High-level modules should not depend on low-level modules. Both should depend on abstractions.
- Abstractions should not depend on details. Details should depend on abstractions.
This design principle inverts the way some people may think about object-oriented programming, dictating that both high- and low-level objects must depend on the same abstraction.
Inversion of Control (IoC)
Another core to this pattern is Inversion of Control (IoC). Typical implementations of this principle use one of the following patterns:
- Factory pattern
- Service locator pattern
- Dependency injection
- Strategy design pattern
Analysis
| Benefit | Notes |
|---|---|
| Plays well with DDD (domain-driven design) | |
| Directed coupling | The most important code in the application depends on nothing, everything depends on it. |
| Flexibility | From an inner-layer perspective, you can swap out anything in any of the outer layers and things should work just fine. |
| Testability | Since the application core does not depend on anything else, it can be easily and quickly tested. |
| Drawback | Notes |
|---|---|
| Learning curve | For some reason, people tend to mess up splitting responsibilities between layers, especially harming the domain model. |
| Indirection | Interfaces everywhere! |
| Potentially heavy | Looking at Palermo’s project, the application core has no dependencies on frameworks due to the abstractions. |
| Multi-layer dependencies | Does not protect outer layers from changes in inner layers. |
| Not use-case focused | This pattern organizes components based on type of function and does not provide any help to discover use cases when taking a high-level look at the code. |
Resources
- Onion Architecture is Interesting by Grzegorz Ziomonski
- Onion Architecture : part 1 by Jeffrey Palermo
- Onion Architecture : part 2 by Jeffrey Palermo
- Onion Architecture : part 3 by Jeffrey Palermo
- Onion Architecture Part 4 by Jeffrey Palermo
Package by Feature
In a typical Layered Architecture, code is often organized based on the layers, with all the components in one layer provided in the same package. This is often called Package by Layer.
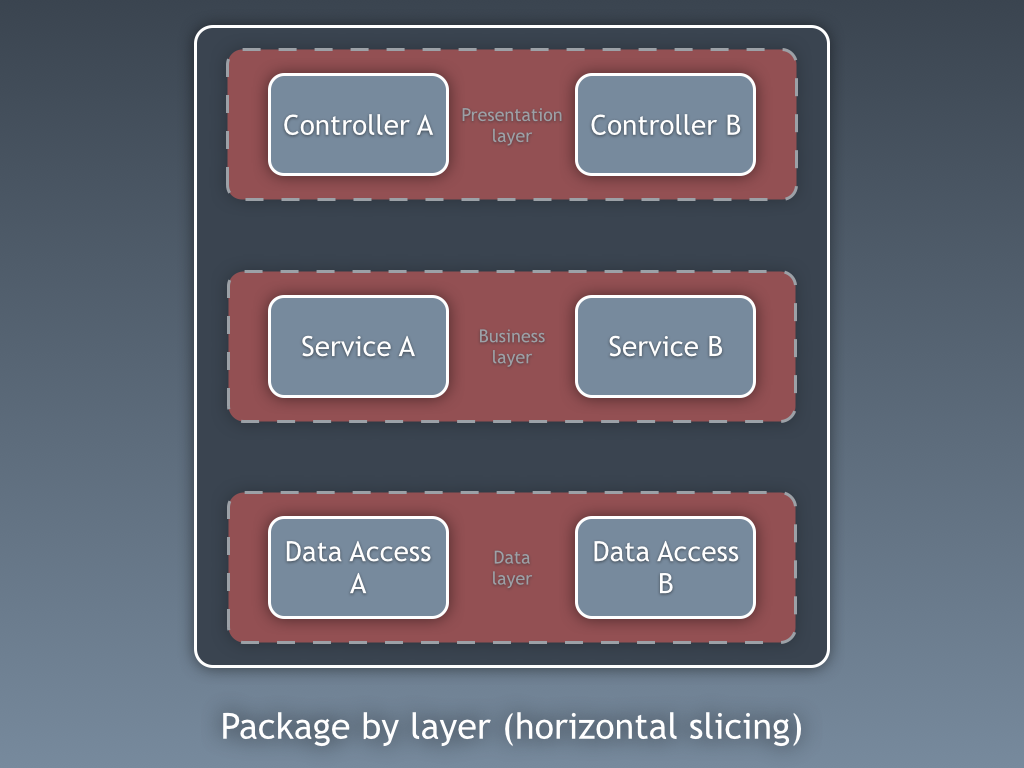
The problem with this approach is that cohesion (the strength of relationships between pieces of functionality) inside each package is usually low and the coupling (the degree of interdependency) between packages is very high. This seems like exactly the opposite of what we want to achieve.
The Package by Feature Architecture pattern attempts to address these concerns by building layers within each feature.
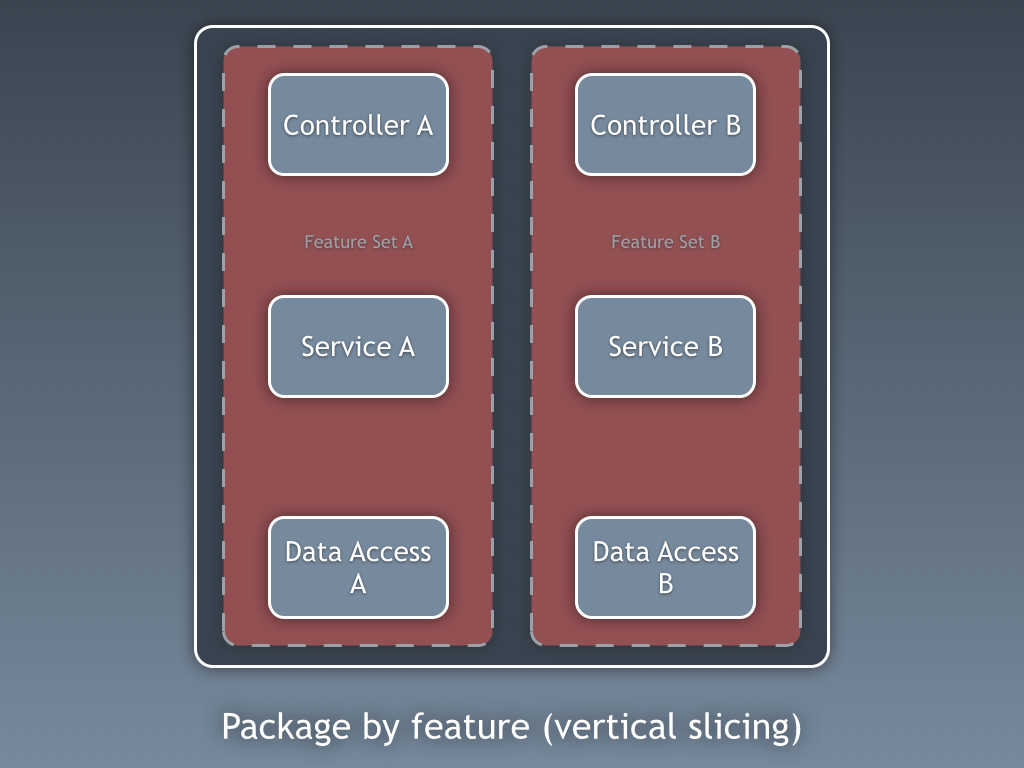
The essence of this pattern can be described like this:
Maintaining high cohesion and low coupling at the package model level and being able to recognize what an application does by looking at its package/module structure.
From Grzegorz Ziomonski:
In a typical Layered Architecture, the cohesion inside a package is low and the coupling between packages is high. We rarely change technologies or conventions regarding a particular layer, comparing to how often we add a single feature, hence low cohesion. And, in most cases, each class in a layer (package) depends on at least one class in another layer (package), making the coupling between them high.
In Package by Feature style, we ideally change classes only in a single package – the one related to the feature we’re working on – so cohesion is high, and there are only a few dependencies between features, so coupling is low.

Analysis
| Benefit | Notes |
|---|---|
| More informative package structure | The system’s main features or behaviors can be deduced from the code structure. |
| High cohesion and low coupling | Components that are packaged together are related to each other, and dependencies on other packages are limited. |
| Better encapsulation | You can make effective use of access modifiers to hide the information that ought to stay hidden. |
| Better growth potential (in the code volume sense) | Unless you develop too big or too small features, you shouldn’t encounter the problem of too big or too many packages. |
| Use cases may be visible | “If features are identified properly, they will tend to represent use cases supported by the application. |
| Drawback | Notes |
|---|---|
| Unspecified feature size | There is no clear guidance or proof that one understanding of feature is better than another. |
| Learning curve | The concept is simple, but since you need to find your own way to slice a system into features, mastering it can be really hard. |
| Messiness potential | In a tangled domain, in which everything is connected to everything, the slicing into features might become artificial and the low coupling promise might not be fulfilled. |
Resources
- Package by Feature is Demanded by Grzegorz Ziomonski
- Package by feature, not layer by Java Practices
- Package by feature by Kostis Kapelonis
- Package by component and architecturally-aligned testing by The Coding Architecture
Clean Architecture
The Clean Architecture, created by Robert “Uncle Bob” Martin, is an attempt at integrating the benefits of all of the other architecture patterns. These include:
- Independent of Frameworks
- Testable
- Independent of UI
- Independent of Database
- Independent of any external agency
This architecture, like the onion architecture, is represented by concentric circles and makes heavy use of a dependency rule:
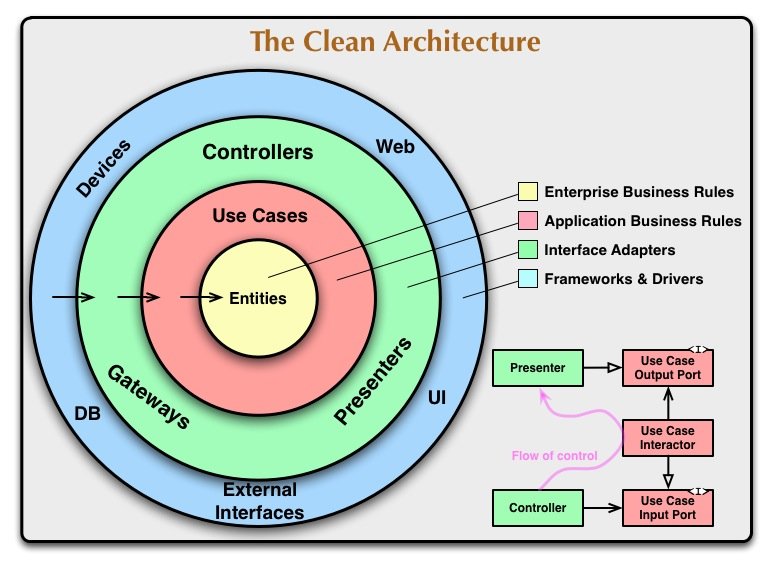
The Dependency Rule
The Dependency Rule for this pattern states that source code dependencies can only point inwards. Nothing in an inner circle can know anything at all about something in an outer circle, similar to the Layered Architecture and unlike the Onion Architecture. So when we pass data across a boundary, it is always in the form that is most convenient for the inner circle.
The layers in this pattern are organized in such a way as to move things that may change further from the center.
- Entities – encapsulate enterprise-wide business rules. An entity can be an object with methods or it can be a set of data structures and functions. They encapsulate the most general and high-level rules and are least likely to change when something external changes (e.g. page navigation or security). No operational change to any particular application should affect the entity layer.
- Use Cases – application-specific business rules, encapsulating and implementing all of the use cases of the system. These use cases orchestrate the flow of data to and from the entities. Changes in this layer should not affect entities, and changes in externalities (databases, UI, common frameworks) should not affect this layer. Changes to the operation of the application will affect the software in this layer.
- Interface Adapters – Like the Hexagonal Architecture, these adapters convert data from the format most convenient for the use cases and entities to the format most convenient for some external agency, such as the database or the UI. This layer will contain the architecture of the GUI (e.g. MVC etc.), including presenters, views, and controllers. This layer will also contain any other adapters necessary to convert data from some external form to an internal form used by the use cases and entities.
- Frameworks and Drivers – frameworks and tools such as database, the web/UI framework, etc. Not much code is written in this layer other than glue code. (One thing I have still to determine is how this glue code is different from interface adapters in the green layer.)
Analysis
| Benefit | Notes |
|---|---|
| Use cases are clearly visible | |
| Flexible | Switching between frameworks, databases, or application servers is explicitly enabled. |
| Testable | The heavy use of interfaces allows tests to be written for any part of the application. |
| No idiomatic framework usage | The application components would not be familiar to a developer who is familiar with focusing on frameworks. |
| Learning curve | It’s harder to grasp than the other styles due to lack of references to frameworks. |
| Indirect | There will be a lot more interfaces than one might expect. |
| Heavy | You might end up with a lot more classes than in projects that follow other architecture patterns. |
Resources
- Clean Architecture is Screaming by Grzegorz Ziomonski
- The Clean Architecture by Robert “Uncle Bob” Martin
- Robert C Martin – Clean Architecture (video)